AI System Privacy Audit: Structured Logging¶
System in scope: doc_quality_compliance_check — structlog-based application logging layer, HTTP request middleware log output, service-level log events, and the relationship between application logs and the persisted audit_events compliance trail.
1. System Diagram¶
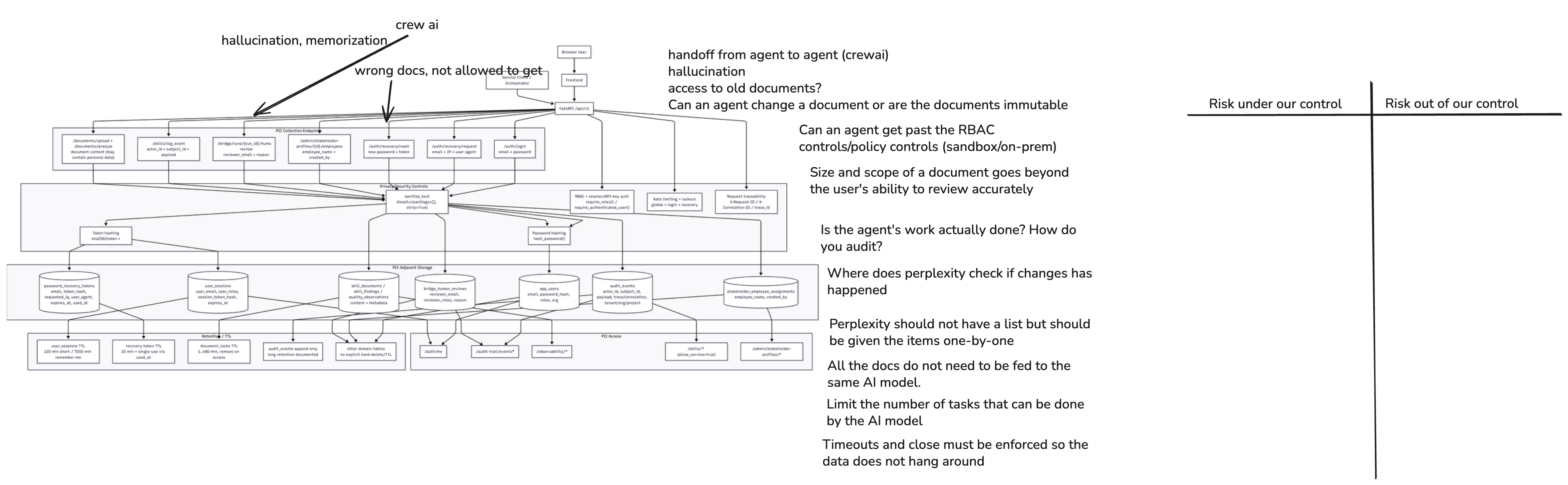
Structured-logging-relevant architecture facts used in this risk sheet:
- The application uses structlog ≥ 24.1.0 configured via
core/logging_config.py, withPrintLoggerFactorywriting to stdout in JSON (production) or console (development) format. - Log format is controlled by
LOG_FORMATenv var (jsonfor production); log level byLOG_LEVEL(defaultINFO). - The HTTP request middleware in
api/main.pybindsrequest_id,correlation_id, andtrace_idas context variables and logs every request withmethod,path,status,duration_ms. - Service-level loggers (
get_logger(__name__)) emit structured events at key decision points: HITL review lifecycle, report generation, research requests, template loading. - The auth route writes
auth.login_success/auth.login_failureevents toaudit_events(PostgreSQL) via thelog_eventservice — not to the structlog stream — but login-related events appear in both surfaces. - Rate-limiting signals (login throttle, recovery throttle) are tracked in-memory per email/IP; abuse events are logged.
- No PII redaction processor is present in the structlog processor chain (
shared_processorscontains onlymerge_contextvars,add_log_level,TimeStamper, and a renderer). - Structlog output goes to stdout; downstream retention, rotation, and access control depend entirely on infrastructure (e.g., Docker log driver, Kubernetes log aggregator, cloud logging service).
2. Data Flow Analysis¶
| Data Flow | Source | Destination | Encrypted? | Logged? | Priority |
|---|---|---|---|---|---|
| HTTP request log entry emitted per request | FastAPI middleware | stdout (structlog) → log aggregator | Depends on infrastructure transport | Every request: method, path, status, duration_ms, request_id, correlation_id, trace_id |
High |
| Auth login event (success / failure) | POST /api/v1/auth/login |
audit_events PostgreSQL table and structlog stream |
In-transit + at-rest DB controls | Email visible as actor_id in audit_events; login outcome logged in structlog |
High |
| Rate-limit / lockout event | core/rate_limit.py, auth route |
structlog stream | Depends on infrastructure | IP address and email appear as identifiers in throttle/lockout events | High |
| Service lifecycle events (HITL, reports, research) | Service layer (hitl_workflow.py, report_generator.py, research_service.py) |
structlog stream | Depends on infrastructure | review_id, document_id, report_id, domain, model, error fields in log lines |
Medium |
| Research API error with domain and model | research_service.py |
structlog stream | Depends on infrastructure | domain, model, error, status_code logged on Perplexity API failure — domain may be business-sensitive |
Medium |
| Application startup / shutdown | api/main.py, orchestrator main.py |
structlog stream | Depends on infrastructure | app_version, environment logged; no credential values in default config |
Low |
DEBUG-level log output (if LOG_LEVEL=DEBUG) |
Any service logger | structlog stream | Depends on infrastructure | May include full request context, raw Pydantic model dumps, provider SDK debug output containing prompts/responses | High |
| structlog output to log aggregator / SIEM | stdout (container runtime) | Log aggregator (e.g., Loki, CloudWatch, Datadog) | Depends on infrastructure configuration | Entire log stream; third-party processor if SaaS aggregator — GDPR Art. 28 applies | High |
Corrected interpretation for GDPR¶
- The HTTP middleware logs
pathfor every request — document paths like/api/v1/documents/doc-abcembed document identifiers; stakeholder paths embed profile IDs. These are personal-data-adjacent fields under GDPR if combined with a timestamp and user identity. - The structlog stream does not log user identity on regular requests (no
user_emailfield in the HTTP middleware), which is a positive privacy-by-design property. However, service-level loggers emitreviewer_emailoractor_idin specific events. - IP address appears implicitly in rate-limit and lockout enforcement — whether it is emitted to the log stream needs verification; IP is personal data under GDPR (CJEU Breyer ruling).
- If a SaaS log aggregator is used (Datadog, Splunk Cloud, CloudWatch), the entire log stream — including any personal data fields — constitutes a transfer to a data processor, requiring a GDPR Art. 28 Data Processing Agreement.
3. Sensitive Data¶
Sensitive Data: User Email in actor_id of Auth Audit Events¶
- Category: Personal data (identified natural person) — GDPR Art. 4(1)
- Examples:
actor_id = "user@example.com"inauth.login_success,auth.login_failure,auth.recovery.requestedevents written toaudit_eventsand referenced in structlog entries - Why Sensitive: Directly identifies users; combined with
event_type,event_time, andpayload.rolescreates a profile of user authentication behaviour; stored in the long-retention audit trail - Current Protection:
audit_eventstable is role-gated; structlog output to stdout (downstream controls depend on infrastructure) - Risk (or Harm) if Exposed: Profiling of user login frequency and role assignments; breach of GDPR Art. 5(1)(f) confidentiality if log stream is accessible beyond authorised operators
Sensitive Data: IP Address in Rate-Limit and Lockout Events¶
- Category: Online identifier — GDPR Art. 4(1); personal data per CJEU Breyer ruling
- Examples: IP address used as key in per-IP login throttle (
auth_login_rate_limit) and recovery throttle; emitted as identifier in abuse-detection log entries - Why Sensitive: IP addresses are personal data under GDPR; stored in-memory rate-limit state and potentially emitted to log stream; if logged to a persistent aggregator, retention must comply with data minimisation obligations
- Current Protection: In-memory rate-limit state (no DB persistence observed); log output depends on infrastructure
- Risk (or Harm) if Exposed: GDPR breach if IP addresses are logged to long-retention aggregators without a legal basis and retention policy; enables correlation of individual users across sessions via IP linkage
Sensitive Data: Document and Entity Identifiers in HTTP Path Log Fields¶
- Category: Indirect personal data (pseudonymous identifiers linkable to persons)
- Examples:
/api/v1/documents/{document_id},/api/v1/stakeholders/{profile_id},/api/v1/bridge/{run_id}— all logged aspathin every HTTP request entry - Why Sensitive: Document IDs and stakeholder profile IDs are pseudonymous references to personal data records; combined with timestamp and source IP they can reconstruct a user's activity trail
- Current Protection: HTTP log entry does not include user email or session ID (positive control); HTTPS in transit
- Risk (or Harm) if Exposed: Re-identification of user activity from log records; access pattern reconstruction; GDPR Art. 5(2) accountability gap if logs are not access-controlled
Sensitive Data: Service-Level Log Fields with Reviewer Identity¶
- Category: Personal data embedded in operational log events
- Examples:
reviewer_emailin HITL workflow log entries (review_created,review_status_updated);actor_id(email) in Skills API skill event log;domainin research service error logs - Why Sensitive: Reviewer email directly identifies a natural person and is logged alongside document IDs and review decisions; persists in log stream for as long as logs are retained
- Current Protection: Structlog output to stdout; no PII redaction processor in chain; retention and access depend on infrastructure
- Risk (or Harm) if Exposed: Reviewer identity linked to specific document review decisions in log records; GDPR violation if logs are retained beyond operational need or shared with third-party aggregators without a DPA
4. Privacy Risks¶
Risk 1: No PII redaction processor in structlog chain — personal data emitted in plaintext¶
- Priority: High
- Risk Category: Logging minimisation and PII scrubbing
- GDPR Reference: Art. 5(1)© — data minimisation; Art. 25 — privacy by design; Art. 32 — security of processing
- Potential Harm/Impact: Emails, document IDs, and reviewer identifiers flow through the structlog processor chain without any scrubbing or pseudonymisation; any consumer of the log stream (log aggregator, on-call engineer, third-party SIEM) receives plaintext personal data; no technical mechanism prevents accidental inclusion of additional sensitive fields in future log entries
- Ability to Implement Control: High
- Recommended controls:
- Add a custom structlog processor (between
TimeStamperand renderer) that redacts or pseudonymises known sensitive field names:reviewer_email,actor_id(if email),user_email,email, and optionallyactor_idvalues matching an email pattern. - Publish a list of permitted log field names in the project coding standards; add a linting rule or test that checks log call sites do not introduce new unlisted PII fields.
- For audit-grade events that require the email (e.g.,
auth.login_success), route them exclusively toaudit_events(DB, role-gated) rather than the structlog stream.
Risk 2: DEBUG log level may expose full request context, model outputs, and provider SDK traces¶
- Priority: High
- Risk Category: Log-level governance and environment hardening
- GDPR Reference: Art. 5(1)© — data minimisation; Art. 32 — security of processing
- Potential Harm/Impact:
LOG_LEVEL=DEBUGis the natural development setting; if accidentally applied to staging or production it exposes full Pydantic model dumps, raw provider API responses (which may contain prompt/output content), and internal service state including personal data; this has occurred in real incidents at comparable systems - Ability to Implement Control: High
- Recommended controls:
- Add a startup assertion: if
environment == "production"andlog_level == "DEBUG", fail application startup with a clear error message. - Default
LOG_LEVELtoWARNINGorINFOin production environment configuration; require an explicit override with a documented justification for any temporaryDEBUGactivation in production. - Ensure provider SDK (Anthropic, Perplexity) debug output is suppressed independently of the application's log level by setting their respective logger levels explicitly to
WARNINGinconfigure_logging().
Risk 3: Log output destination and retention are fully infrastructure-delegated with no application-level policy¶
- Priority: High
- Risk Category: Log retention governance and GDPR storage limitation
- GDPR Reference: Art. 5(1)(e) — storage limitation; Art. 30 — record of processing; Art. 28 — data processor (if SaaS aggregator)
- Potential Harm/Impact:
PrintLoggerFactorywrites to stdout; all retention, rotation, access control, and deletion are delegated to whatever log aggregator is configured at deployment time; there is no application-level policy that says "structured logs must not be retained for more than N days" or "access to log streams is restricted to operator role Y"; if a SaaS aggregator is used (Datadog, Splunk Cloud, CloudWatch), the entire log stream is processed by a third party without a mandatory GDPR Art. 28 agreement in the current implementation - Ability to Implement Control: Medium
- Recommended controls:
- Define a maximum log retention period (e.g., 30 days for operational logs;
audit_eventsDB trail serves long-term compliance needs) in the deployment runbook and enforce it in the log aggregator configuration. - Document the log aggregator vendor(s) in the GDPR Record of Processing Activities as data processors; ensure a signed DPA is in place before sending logs to any SaaS service.
- Add log stream access control to the infrastructure design: restrict log query access to the same roles that can access the
audit_eventsAPI (qm_lead,auditor,riskmanager).
Risk 4: IP address handling in rate-limit events is undocumented for GDPR purposes¶
- Priority: Medium
- Risk Category: Online identifier data governance
- GDPR Reference: Art. 4(1) — definition of personal data (IP as online identifier); Art. 5(1)(e) — storage limitation
- Potential Harm/Impact: Login and recovery rate-limit logic uses IP address as a throttle key; if the IP is included in structlog event fields (e.g., in a
client_iporremote_addrfield on abuse events), it becomes part of the log stream and is subject to GDPR; in-memory storage means no persistence but also no audit of abuse patterns; unclear if IP is emitted to persistent log aggregator - Ability to Implement Control: High
- Recommended controls:
- Review all log call sites in
auth.pyandrate_limit.pyto confirm whetherclient_ipor equivalent is emitted; if so, hash it (SHA-256 with a service-specific salt) before logging. - Document the IP address processing in the GDPR Record of Processing Activities: purpose (abuse prevention), legal basis (legitimate interest), retention (in-memory only — no persistence), and minimisation measure (hashed if logged).
Risk 5: Structlog and audit_events serve overlapping but inconsistent purposes — risk of duplication and compliance confusion¶
- Priority: Medium
- Risk Category: Audit trail governance and data duplication
- GDPR Reference: Art. 5(2) — accountability; Art. 30 — record of processing
- Potential Harm/Impact: Some events (e.g., login success, review lifecycle) appear in both the structlog stream and
audit_eventsPostgreSQL table. This creates two sources of truth with different schemas, retention periods, and access controls; inconsistency between them complicates GDPR breach investigation, subject access requests, and external audit responses; structlog entries may contain more detail thanaudit_eventsor vice versa - Ability to Implement Control: High
- Recommended controls:
- Define a clear event routing rule: compliance-critical events (auth, document actions, review decisions, workflow completions) go exclusively to
audit_events(DB, structured, role-gated); operational events (latency, retry, routing mode, startup) go to structlog stream only. - Remove or suppress the structlog emission of events that are already persisted to
audit_eventsto eliminate dual-stream confusion. - Document the routing rule in the OBSERVABILITY_LOGGING_README and enforce via a code review checklist item.
5. Cross-Sheet Consistency¶
| Control Area | Related Risk Sheet | Alignment Required |
|---|---|---|
| PII in log fields | Risk Sheet 3 (Telemetry) | Same redaction-processor approach applies to both structlog stream and pre-write quality observation service |
| Log aggregator SaaS DPA | Risk Sheet 3 (Telemetry) | OTLP backend and log aggregator must both appear in the GDPR Art. 28 processor register |
audit_events dual-write from structlog |
Risk Sheet 2 (RBAC, Risk 3) | Access-decision log (recommended in sheet 2) should route to audit_events, not to the structlog stream, to benefit from role-gated access |
| DEBUG mode in production | Risk Sheet 1 (Model Providers) | DEBUG output from provider SDKs could expose full prompt/output content — startup guard must cover SDK-level loggers as well |
| IP address logging | Risk Sheet 2 (RBAC, Risk 4) | Bootstrap credential brute-force protection relies on IP throttle; IP handling must be consistent across auth and rate-limit code paths |
Additional information from the repo¶
Brief summary of how this repository uses structlog for JSON-friendly, field-oriented logs, with emphasis on document review and orchestration workflows (not IDE “coding” sessions).
Stack and configuration¶
- Library: structlog (see
pyproject.tomlfor the pinned version). - Central setup:
src/doc_quality/core/logging_config.py—configure_logging(log_level, log_format)merges context variables, adds log level and ISO timestamps, then renders either JSON (LOG_FORMAT=json) or a console dev renderer (LOG_FORMAT=console, default). - Bootstrap: the main FastAPI app calls
configure_loggingin its lifespan hook (src/doc_quality/api/main.py). The standalone orchestrator (services/orchestrator/) usesstructlog.get_logger(__name__)for workflow services; it does not currently reuselogging_config.configure_loggingin its lifespan (startup still emits structuredorchestrator_starting/orchestrator_stoppingevents).
For full observability (OTel, metrics, audit tables), see OBSERVABILITY_LOGGING_README.md at the repo root.
Request-scoped context (correlating HTTP to downstream work)¶
HTTP middleware in src/doc_quality/api/main.py clears and binds structlog context variables per request:
request_id— fromX-Request-IDor a new UUID.correlation_id— fromX-Correlation-IDor the same asrequest_id.trace_id— OpenTelemetry trace hex when tracing is active, then merged into context before the access log line.
Each request logs a single structured event, http_request, with method, path, status, duration_ms, and trace_id. Those context vars are merged into subsequent log lines from the same request when code uses the shared processor chain (see merge_contextvars in logging_config.py).
Workflow tracking (orchestrator)¶
The document review flow (services/orchestrator/src/doc_quality_orchestrator/flows/document_review_flow.py) logs orchestration decisions and outcomes with stable event names and IDs:
| Event | Purpose |
|---|---|
crewai_not_available_forced_fallback / crewai_kill_switch_active |
Routing warnings when CrewAI path is unavailable or disabled |
workflow_run_timeout |
Global run timeout with run_id and limit |
crew_workflow_starting / crew_workflow_completed |
Crew path: run_id, trace_id, workflow_id, optional document_id, verifier and validator summary fields |
scaffold_workflow_completed |
Single-agent fallback path completion with run_id, trace_id, workflow_id, provider |
Dual trail: the flow also posts structured payloads to the backend Skills audit API (skills_api.log_event) for events such as workflow_routing_decision, crew_workflow_completed, and workflow_run_completed. Those rows support compliance-style audit; structlog lines support live operations and log aggregation.
Step-level execution (limits and crew bookkeeping)¶
services/orchestrator/src/doc_quality_orchestrator/runtime_limits.py implements RuntimeLimitEnforcer, which logs:
step_limit_exceeded/token_limit_exceeded— limit breaches withreasonandrun_idstep_execution_recorded— each recorded step withstep_id,agent_id,step_number,attempt,status,duration_seconds,tokens_consumed
Together with flow-level events, this gives a granular timeline of agent/tool steps inside a workflow run.
Backend domain workflows (Skills API and HITL)¶
Structured logs in src/doc_quality/services/skills_service.py track the document pipeline: e.g. skill_document_persisted, skill_document_workflow_status_updated, skill_text_extracted, skill_finding_written, and skill_event_logged (mirrors persisted audit events).
Human-in-the-loop state changes are logged in src/doc_quality/services/hitl_workflow.py (review_created, review_not_found, review_status_updated). Document analysis and compliance paths use similarly named events in document_analyzer.py, compliance_checker.py, etc.
Conventions for operators¶
- Prefer keyword arguments on log calls (
logger.info("event_name", key=value)) so JSON output has queryable fields. - Correlate cross-service behavior with
run_id/trace_idfrom orchestrator logs andrequest_id/correlation_idfrom API middleware. - Use
LOG_FORMAT=jsonin production so log platforms can indexevent,timestamp, and custom fields without regex parsing.
Source pointers¶
| Area | Path |
|---|---|
| Logging setup | src/doc_quality/core/logging_config.py |
| HTTP + contextvars | src/doc_quality/api/main.py |
| Flow + crew/scaffold | services/orchestrator/.../flows/document_review_flow.py |
| Step limits | services/orchestrator/.../runtime_limits.py |
| Skills + audit mirror | src/doc_quality/services/skills_service.py |
| HITL | src/doc_quality/services/hitl_workflow.py |