AI System Privacy Audit: Model Provider Risks and Mitigations¶
System in scope: doc_quality_compliance_check (backend + orchestrator + observability).
1. System Diagram¶
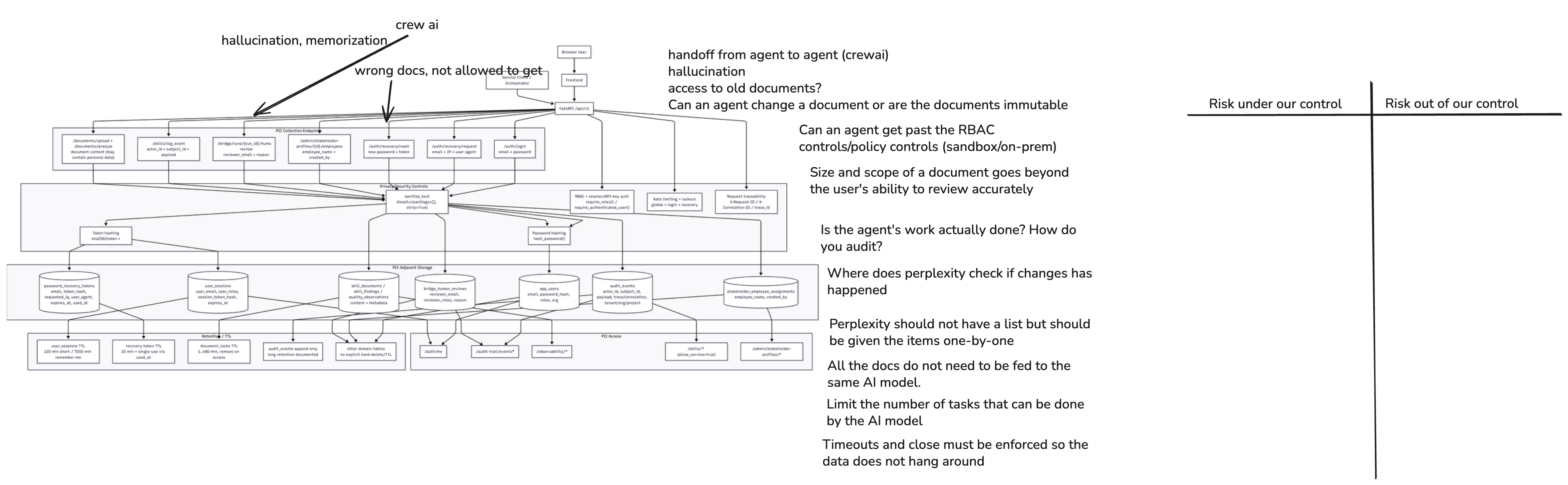
Model-relevant architecture facts used in this risk sheet:
- The backend/orchestrator uses a model adapter layer (Anthropic, OpenAI-compatible, Nemotron target/scaffold).
- Prompt/output traces are exposed and persisted for observability and audit workflows.
- The product already includes anti-hallucination signals and a validator stage, but model outputs can still be wrong or overconfident.
2. Data Flow Analysis¶
| Data Flow | Source | Destination | Encrypted? | Logged? | Priority | Action Point | Implemtation |
|---|---|---|---|---|---|---|---|
| User document/text submission (may include personal data) | Frontend user session | FastAPI API routes (/documents/*, workflow endpoints) |
In-transit (HTTPS/TLS) | Request + audit metadata; selected payload fields in audit/observability paths | High | 1. Document meta data (e.g. author, role, time of change, change topic ...). use pseudonymization techniques on private data. Role based data exist in postgres db (mandatory profiles). Mask private data in change history meta data table depending on role and for final output. 2. Document content proof about PII data in text, images and link targets. | Yes |
| Workflow context assembly for model call | FastAPI/Orchestrator | Model adapter layer | Internal service transport (TLS in deployment) | Yes (workflow/audit events) | High | 1. Orchestrator to block activities outside of the models sandbox. 2. Use pydantic/FastAPI library to validate the data meets the required schema; similar to data loss prevention frameworks like MS Purview | Yes |
| Prompt payload to model provider (current state) | Model adapter | External provider endpoint (Anthropic/OpenAI-compatible/Nemotron target) | In-transit (HTTPS/TLS) | Provider metadata and local audit/trace logs | High | local model sandbox / no external models | Yes |
| Model completion returned to service | External provider | Model adapter + orchestrator flow | In-transit (HTTPS/TLS) | Yes (quality traces, run/step events) | High | like above | maybe |
| Prompt/output pair persistence | Orchestrator/quality service | PostgreSQL observability/audit records | In-transit + at-rest DB controls | Yes (explicitly persisted) | High | Prompt check for PII data. | maybe |
| Quality telemetry view (provider, model, prompt/output, rich payload) | Backend observability endpoints | Admin UI (/admin/observability) |
In-transit (HTTPS/TLS) | Access path is auditable | High | Check tracing output for PII data. | no |
| On-prem target model invocation (target state) | Model adapter | Internal model gateway/cluster (private network) | In-transit (mTLS recommended) | Yes (internal trace + governance logs) | High | Check tracing & logging output for PII data. | no |
| Shadow evaluation during migration | Adapter dual-run mode | External + internal models (temporarily) | In-transit (TLS/mTLS) | Yes (comparison-only dataset, restricted retention) | Medium | Model in sandbox and usage of synthetic dataset. | no |
Corrected interpretation for privacy¶
- The critical privacy boundary is not only frontend-to-backend, but backend/orchestrator-to-model-provider.
- The highest-risk payload is the full prompt context plus model output, because both may contain direct or indirect personal data.
- Observability improves governance but increases privacy exposure if traces are over-retained or insufficiently redacted.
3. Sensitive Data¶
Sensitive Data: Prompt Context and Model Output Content¶
- Category: Input/output content containing direct or inferred personal data
- Examples: Names, emails, stakeholder assignments, reviewer identifiers, document passages copied into prompts, generated summaries that may restate personal data
- Why Sensitive: Leaves the primary application context during model inference (current external-provider path)
- Current Protection: Session auth, RBAC, TLS, audit events, optional graceful fallback without external model key
- Risk (or Harm) if Exposed: Unauthorized disclosure, regulatory non-compliance (GDPR purpose limitation/data minimization), reputational harm
Sensitive Data: Provider/Model Telemetry and Rich Trace Payload¶
- Category: Metadata linked to actors, workflows, and potentially sensitive content fingerprints
- Examples:
provider,model_used,trace_id,correlation_id, latency/tokens, rich payload entries, prompt/output snapshots - Why Sensitive: Enables reconstruction of who triggered what model action and when; can become re-identifiable when combined with audit tables
- Current Protection: Backend-protected endpoints, role checks, PostgreSQL persistence
- Risk (or Harm) if Exposed: Excessive internal visibility, inference attacks, unauthorized profiling of users/reviewers
Sensitive Data: Model Credentials and Routing Configuration¶
- Category: Secrets and control-plane configuration
- Examples: API keys, adapter routing flags, provider selection settings
- Why Sensitive: Compromise enables data exfiltration or unauthorized model usage
- Current Protection: Environment-based secret configuration and backend auth controls
- Risk (or Harm) if Exposed: Account abuse, data leakage, loss of integrity of compliance decisions
4. Privacy Risks¶
Risk 1: External model transfer of potentially personal prompt/output data¶
- Priority: High
- Risk Category: Model data transfer and residency
- Potential Harm/Impact: Data leaves controlled environment; third-party processing and cross-border concerns
- Ability to Implement Control: Medium
- Recommended controls:
- Replace external inference path with internal on-prem model gateway as default.
- Keep adapter interface stable so provider swap does not change business logic.
- Enforce strict egress policy: only approved internal model endpoints from production.
Risk 2: Over-collection and over-retention in model observability traces¶
- Priority: High
- Risk Category: Logging/telemetry minimization
- Potential Harm/Impact: Prompt/output traces may store unnecessary personal data for too long
- Ability to Implement Control: High
- Recommended controls:
- Apply pre-persistence redaction policy for prompt/output trace fields.
- Separate "operational" vs "audit-evidence" retention classes with explicit TTLs.
- Restrict raw trace visibility to least-privilege roles and log all access.
Risk 3: Hallucinated model output impacts compliance decisions¶
- Priority: High
- Risk Category: Model output reliability and decision integrity
- Potential Harm/Impact: Wrong legal/compliance guidance, missed obligations, false audit confidence
- Ability to Implement Control: Medium
- Recommended controls:
- Keep mandatory validator stage and add citation-required answer format.
- Add grounding checks against rule packs before output is accepted.
- Require HITL approval for high-impact outputs.
Risk 4: Model/version drift reduces reproducibility and explainability¶
- Priority: Medium
- Risk Category: Governance and traceability
- Potential Harm/Impact: Same input yields diverging output without clear reason; weak audit defensibility
- Ability to Implement Control: Medium
- Recommended controls:
- Persist model version, adapter version, prompt template version, and config hash for every run.
- Freeze approved model release sets per environment.
- Run periodic regression suite on reference compliance tasks.
Risk 5: Migration to on-prem models may degrade quality if unmanaged¶
- Priority: Medium
- Risk Category: Migration and model quality assurance
- Potential Harm/Impact: Quality drop or hidden failure modes could shift risk from privacy to governance failure
- Ability to Implement Control: High
- Recommended controls:
- Build a benchmark set from real workflows (privacy-scrubbed), including hallucination-sensitive cases.
- Use shadow mode (external vs on-prem) with acceptance thresholds before cutover.
- Define release gates: factuality, citation correctness, latency, and refusal behavior.
5. On-Prem Migration Plan (Quality-Preserving)¶
Target objective: remove external GenAI dependency for production personal-data paths while maintaining or improving compliance-output quality.
- Adapter-first migration: keep orchestration and API contracts unchanged; switch routing in adapter layer.
- Dual-run validation: run external and on-prem in parallel for a controlled period on the same scrubbed inputs.
- Quality gate: promote on-prem only when benchmark thresholds are met (accuracy, hallucination rate, explainability/citations, latency).
- Privacy hardening: enforce prompt minimization, redaction, and retention classes before and after cutover.
- Operational fallback: if on-prem model confidence/validator checks fail, route to deterministic rules + HITL instead of external provider.
This sequence preserves output quality while reducing privacy exposure and external model dependency.
Mitigations and Controls¶
| Risk | Mitigation or Control | Review | Reduction or Impact Change | Implement? (y/n) |
|---|---|---|---|---|
| Risk 1: External model transfer of potentially personal prompt/output data | On-prem migration plan | We analyzed substituting local models. | Risk of sensitive data exposure to 3rd parties reduced | y |
| Risk 1: External model transfer of potentially personal prompt/output data | Run parallel on-prem and external models on the same scrubbed inputs | We will analyze what differences are observed in leakage of data between the two solutions. | Risk of sensitive data leakage by external quantitative estimate relative to on-prem | y |
| Risk 1: Quality gate: promote on-prem only when benchmark thresholds are met (accuracy, hallucination rate, explainability/citations, latency). | Use external provider only when on-prem is insufficient | We will analyze conditions where external models meaningfully outperform on-prem. | Risk of sensitive data exposure by reducing reliance on external models | y |
| Risk 1: External model transfer of potentially personal prompt/output data | Operational fallback to human in the loop (HITL) | We analyzed conditions where human review is necessary. | Risk of sensitive data exposure to 3rd parties reduced | y |
| Risk 2: Over-collection and over-retention in model observability traces | n | |||
| Risk 3: Hallucinated model output | n | |||
| Risk 4: Model/version drift | n | |||
| Risk 5: Migration to on-prem models may degrade quality if unmanaged | n |
Appendix¶
Additional information from the repo source code
Subprocessor egress — Anthropic and Perplexity
Perplexity (src/doc_quality/services/research_service.py)¶
When: PERPLEXITY_API_KEY is non-empty.
Prompt content: Built from ResearchRequest: domain, description, target_market, and optional custom_query (or default research question) via prompts/research_prompt_v1.txt.
When key is empty: Static fallback; no HTTP call to Perplexity (still builds query string for ResearchResult).
Research API persistence (src/doc_quality/api/routes/research.py)¶
When result.provider == "perplexity", the API calls create_quality_observation with payload containing:
llm_prompt(full built prompt),llm_output(full model answer),- provider metadata and citation counts.
These are stored in quality_observations.payload (src/doc_quality/services/quality_service.py). This duplicates potentially sensitive user text on disk in addition to sending it to Perplexity.
Anthropic — risk template AI suggest (src/doc_quality/api/routes/risk_templates.py)¶
When: ANTHROPIC_API_KEY set; route ai-suggest.
Sent to Anthropic: System prompt (FMEA vs RMF), optional request.context (product/system context), partial_row as JSON, and instructions. Not full documents unless context or row fields contain them.
Anthropic — document analysis agent (src/doc_quality/agents/doc_check_agent.py)¶
Implementation: Sends up to 2000 characters of document content plus document_type and rule-based issues in the user message.
Wiring: DocumentCheckAgent is not referenced elsewhere in the Python tree (only defined in this file). The live analyze_document path uses document_analyzer.analyze_document only — rule-based, no LLM in current API flows. Treat as dead integration risk if something imports it later.
Compliance agent (src/doc_quality/agents/compliance_agent.py)¶
Creates an Anthropic client when a key exists but check_compliance delegates to compliance_checker only (no Anthropic messages observed in compliance_checker.py).
Orchestrator service (services/orchestrator/)¶
Separate process; AnthropicAdapter is scaffold-style. Boundary review: whatever workflows you enable may forward document fragments to backends — trace per workflow when operating this service.
Subprocessor summary¶
| Vendor | Trigger | Typical data categories |
|---|---|---|
| Perplexity | /api/v1/research/regulations with API key |
Product domain, description, markets, optional free-text query → also persisted in DB as prompt+answer. |
| Anthropic | Risk template ai-suggest |
Free-text context + partial row JSON. |
| Anthropic | DocumentCheckAgent |
First 2k chars of document + issues — not used by default document routes today. |